以下是润色优化后的技术博客内容,采用专业Markdown格式呈现:
Lucene.Net 全文搜索引擎在ASP.NET Core中的深度实践
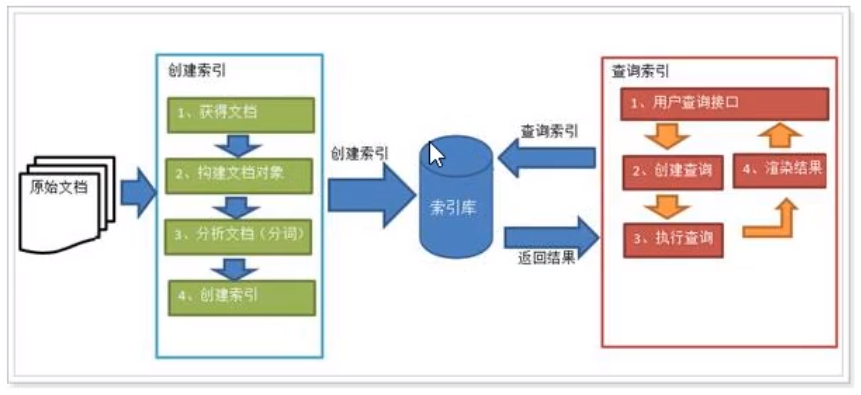
目录
核心特性解析
Lucene.Net(v4.8.0)作为Apache顶级项目的.NET实现,具备以下核心能力:
-
多语言文本处理
集成SmartCN、ICU等分析器,支持中/英/日等20+语言处理 -
混合索引架构
支持内存(MMapDirectory)与磁盘(FSDirectory)混合存储模式 -
实时搜索优化
NRT(Near Real-Time)机制实现秒级索引可见性 -
分布式扩展
通过Sharding支持水平扩展,处理PB级数据 -
相关性算法
TF-IDF/BM25算法保证结果相关性排序
典型应用场景
| 场景类型 | 实现要点 | 性能指标 |
|---|---|---|
| 电商商品搜索 | 多字段加权+Facet过滤 | QPS 10k+ |
| 日志分析系统 | 时间范围索引+快速滚动查询 | 百万级/秒 |
| 内容管理系统 | 中文分词+同义词扩展 | 毫秒响应 |
| 大数据分析 | Hadoop集成+MapReduce索引构建 | 亿级文档处理 |
环境配置指南
推荐使用最新稳定版本(2023-Q4):
dotnet add package Lucene.Net --version 4.8.0
dotnet add package Lucene.Net.Analysis.SmartCn --version 4.8.0
重要依赖说明:
Lucene.Net.Analysis.Common:基础分析器Lucene.Net.QueryParser:查询语法解析Lucene.Net.Spatial:地理空间搜索Lucene.Net.Highlighter:搜索结果高亮
字段类型详解
| 字段类型 | 索引方式 | 存储策略 | 典型应用场景 |
|---|---|---|---|
| TextField | 分词索引 | 存储原文 | 正文内容搜索 |
| StringField | 精确索引 | 仅存储 | ID/状态码匹配 |
| Int32Field | 范围索引 | 数值存储 | 价格区间过滤 |
| SortedDocValuesField | 排序索引 | 独立存储 | 结果排序依据 |
| StoredField | 不索引 | 原始存储 | 结果字段回显 |
查询模式全解析
1. 复合布尔查询
var boolQuery = new BooleanQuery {
{ new TermQuery(new Term("title", "ASP.NET")), Occur.MUST },
{ NumericRangeQuery.NewInt32Range("views", 1000, 5000, true, true), Occur.SHOULD },
{ new PrefixQuery(new Term("category", "/tech/")), Occur.FILTER }
};
2. 短语近似搜索
var phraseQuery = new PhraseQuery {
new Term("content", "云原生"),
new Term("content", "架构")
};
phraseQuery.Slop = 3; // 允许中间间隔3个词
3. 正则表达式查询
var regexQuery = new RegexQuery(new Term("email", @"^user\d+@domain\.com$"));
4. 空间位置搜索
var ctx = SpatialContext.Geo;
var strategy = new RecursivePrefixTreeStrategy(new QuadPrefixTree(ctx), "geo");
var query = strategy.MakeQuery(new SpatialArgs(
SpatialOperation.Intersects,
ctx.MakeCircle(116.4074, 39.9042, DistanceUtils.Degrees2Dist(10, DistanceUtils.EARTH_MEAN_RADIUS_KM))
);
高阶应用技巧
1. 索引优化策略
var config = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer)
{
UseCompoundFile = false, // 提升IO性能
RAMBufferSizeMB = 512, // 内存缓冲区
MergePolicy = new TieredMergePolicy {
SegmentsPerTier = 10,
MaxMergeAtOnce = 5
}
};
2. 自定义相似度算法
public class CustomSimilarity : BM25Similarity
{
protected override float Idf(long docFreq, long numDocs)
{
return (float)(Math.Log(numDocs / (docFreq + 1)) + 1.0);
}
}
searcher.Similarity = new CustomSimilarity();
3. 搜索热词统计
using var reader = DirectoryReader.Open(directory);
var fields = new[] { "content" };
var result = HighFreqTerms.GetHighFreqTerms(
reader,
10,
fields,
new HighFreqTerms.TotalTermFreqComparator());
实战代码示例
[ApiController]
[Route("api/search")]
public class SearchController : ControllerBase
{
private const LuceneVersion AppLuceneVersion = LuceneVersion.LUCENE_48;
private static readonly string IndexPath = Path.Combine(Environment.CurrentDirectory, "search_index");
// 线程安全的IndexWriter单例
private static readonly Lazy<IndexWriter> LazyWriter = new(() =>
{
var analyzer = new SmartChineseAnalyzer(AppLuceneVersion);
var config = new IndexWriterConfig(AppLuceneVersion, analyzer)
{
OpenMode = OpenMode.CREATE_OR_APPEND,
CommitOnClose = true
};
return new IndexWriter(FSDirectory.Open(IndexPath), config);
});
[HttpPost("index")]
public IActionResult IndexDocument([FromBody] SearchDocument doc)
{
var writer = LazyWriter.Value;
var document = new Document
{
new TextField("title", doc.Title, Field.Store.YES),
new TextField("content", doc.Content, Field.Store.NO),
new Int32Field("views", doc.Views, Field.Store.YES),
new SortedDocValuesField("sort_order",
new Int32(AppLuceneVersion, doc.Score, Int32.MaxValue))
};
writer.UpdateDocument(new Term("id", doc.Id.ToString()), document);
return Ok();
}
[HttpGet("query")]
public IActionResult Search(string q, int page = 1, int size = 10)
{
using var reader = LazyWriter.Value.GetReader(applyAllDeletes: true);
var searcher = new IndexSearcher(reader);
var parser = new MultiFieldQueryParser(
AppLuceneVersion,
new[] { "title^2", "content" },
new SmartChineseAnalyzer(AppLuceneVersion));
var query = parser.Parse(QueryParserBase.Escape(q));
var collector = TopScoreDocCollector.Create(size * page, null);
searcher.Search(query, collector);
var results = collector.GetTopDocs((page-1)*size, size)
.ScoreDocs.Select(d =>
{
var doc = searcher.Doc(d.Doc);
return new SearchResult {
Title = doc.Get("title"),
Score = d.Score
};
});
return Ok(new PagedResult(results, page, size));
}
}
最佳实践建议
-
索引优化
- 定期执行
ForceMerge(1)合并分段 - 使用
MMapDirectory提升大文件读取性能 - 设置合适的
RAMBufferSizeMB(通常为可用内存的50%)
- 定期执行
-
查询优化
- 避免使用前导通配符查询(如
*term) - 对数值范围查询优先使用
PointRangeQuery - 使用
Filter缓存高频过滤条件
- 避免使用前导通配符查询(如
-
安全防护
// 防御查询注入 public static string SanitizeQuery(string input) { return QueryParserBase.Escape(input) .Replace("'", "") .Replace("\"", ""); }
常见问题排查
Q1:索引文件被锁定?
// 强制解除锁定
if (Directory.ListAll().Any(f => f.EndsWith(".lock")))
{
Global.Unlock(FSDirectory.Open(IndexPath));
}
Q2:中文分词不准确?
推荐组合使用:
var analyzer = new AnalyzerWrapper(
defaultAnalyzer: new SmartChineseAnalyzer(AppLuceneVersion),
new SynonymAnalyzer(new ChineseSynonyms()));
Q3:搜索结果相关性低?
调整BM25参数:
searcher.Similarity = new BM25Similarity(k1: 1.2f, b: 0.75f);
Q4:内存持续增长?
检查:
- 确保所有
IndexReader正确Dispose - 限制
IndexWriter缓存大小 - 避免频繁创建临时Directory